Como fazer classificação binária de textos
October 16, 2018
Olá, seja bem vindo(a) a mais um tópico na série de estudo sobre Tensorflow. Hoje iremos implementar uma rede neural para uma tarefa de classificação de texto usando avaliações de filmes como base de dados, ou em outras palavras, com base na avaliação de revisores iremos classificá-la em positiva ou negativa. A classificação binária é um importante tipo de aplicação do aprendizado de máquina. Espero que você já tenha preparado seu ambiente para rodar os scripts, senão, confira os links ao final do post e siga a opção desejada. Antes de continuar, você precisa estar familiarizado com os conceitos de aprendizado de máquina. Uma boa referência é o machine learning crash course produzido pela google.

O conjunto de dados IMDB será usado para treinamento do modelo. O IMDB contém 50.000 revisões em forma de texto e será divido em 25.000 revisões para treino e 25.000 revisões para o teste. Esta divisão está balanceada, ou seja, a proporção entre avaliações positivas e negativas são iguais.
O objetivo deste post é treinar um modelo de rede neural para classificação texto relacionado a avaliações de filmes. Ao terminar a leitura, você será capaz de:
- carregar o conjunto de dados IMDb para treinamento
- explorar e preprocessar os dados de treinamento
- construir seu modelo com o TensorFlow
- treinar, avaliar e fazer predições com seu modelo.
Assim como no post anterior, vamos usar o pacote tf.keras, uma api de alto nível do TensorFlow para construir e treinar o modelo.
O trecho do código a seguir importa os pacotes necessários para nosso script rodar tranquilamente.
import tensorflow as tf
from tensorflow import keras
import numpy as np
Carregando o conjunto de dados IMDB
Para fins de testes, os dados do IMDB já vem empacotado junto com o TensorFlow. Além disso, para facilitar ainda mais a vida do programador, eles já vem pré-processados de tal maneira que as avaliações (sequência de palavras) foram convertidas em uma sequência de números inteiros, onde cada número representa uma palavra específica no dicionário.
Use o código a seguir para fazer o download dos dados para sua máquina (ou uma cópia em cache se já tiver feito)
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17465344/17464789 [==============================] - 0s 0us/stepO argumento num_words=10000 mantém as top 10.000 ocorrências de palavras nos dados de treinamento. As palavras raras são descartadas para manter o tamanho da base gerenciável.
Nota que o procedimento de dividir os dados em conjunto de treino e teste foi feito automaticamente ao importar e carregar a base IMDb. Isso facilita muito o processo de aprendizagem, porém, não acontece no mundo real. Quando estiver trabalhando com sua própria base, você terá que fazer isso manualmente.
Explorando os dados
É importante conhecer os dados que temos em mãos antes de iniciar o treinamento do modelo. Como dito anteriormente, essa base já vem pré-processada de modo que cada exemplo é um array de inteiros representado as palavras de uma avaliação de filme. Cada rótulo é um valor inteiro 0 ou 1, onde 0 siginifica uma avaliação negativa e 1 significa uma avaliação positiva. Use o comando len para confirmar o número de exemplos.
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))Training entries: 25000, labels: 25000Para confirmar se de fato o texto das avaliações foram convertidos em números inteiros, onde cada número representa uma palavra no dicionário, imprima o primeiro exemplo dos dados de treinamento da seguinte maneira:
print(train_data[0])[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]Vale ressaltar que cada avaliação pode ter diferentes tamanhos. O código abaixo mostra a diferença de tamanho entre a primeira e a sugunda avaliação. Uma vez que as entradas em uma rede neural devem possuir tamanho fixo, essa diferença deve ser removida.
len(train_data[0]), len(train_data[1])(218, 189)Transformando números inteiros em palavras
Talvez seja útil saber como fazer a transformação inversa, ou seja, como transformar um array de números inteiros em uma sequência de palavras. O código a seguir criar uma função auxiliar para consultar o objeto dicionário que contém os indíces para mapear em texto.
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json
1646592/1641221 [==============================] - 0s 0us/stepAgora podemos acessar o texto da primeira avaliação, por exemplo, ao invés se uma sequência de números inteiros usando o método decode_review:
decode_review(train_data[0])" this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert is an amazing actor and now the same being director father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also to the two little boy's that played the of norman and paul they were just brilliant children are often left out of the list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"Ajustando os dados de entrada
As avaliações (array de números inteiros) precisam ser convertidos para tensores antes de alimentarem a entrada da rede neural. Essa conversão pode ser feita preenchendo os arrays de modo que eles tenham o mesmo tamanho. E então criar os tensores no formato max_length * num_reviews. A camada Embedding é capaz de fazer esse tipo de manipulação se utilizarmos na primeira camada de nosso modelo.
Para preencher os arrays de modo que possuam o mesmo tamanho, utilize a função pad_sequences.
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)Note como agora os dados possuem o mesmo tamanho:
len(train_data[0]), len(train_data[1])(256, 256)Observe também como a primeira avaliação foi preenchida:
print(train_data[0])[ 1 14 22 16 43 530 973 1622 1385 65 458 4468 66 3941
4 173 36 256 5 25 100 43 838 112 50 670 2 9
35 480 284 5 150 4 172 112 167 2 336 385 39 4
172 4536 1111 17 546 38 13 447 4 192 50 16 6 147
2025 19 14 22 4 1920 4613 469 4 22 71 87 12 16
43 530 38 76 15 13 1247 4 22 17 515 17 12 16
626 18 2 5 62 386 12 8 316 8 106 5 4 2223
5244 16 480 66 3785 33 4 130 12 16 38 619 5 25
124 51 36 135 48 25 1415 33 6 22 12 215 28 77
52 5 14 407 16 82 2 8 4 107 117 5952 15 256
4 2 7 3766 5 723 36 71 43 530 476 26 400 317
46 7 4 2 1029 13 104 88 4 381 15 297 98 32
2071 56 26 141 6 194 7486 18 4 226 22 21 134 476
26 480 5 144 30 5535 18 51 36 28 224 92 25 104
4 226 65 16 38 1334 88 12 16 283 5 16 4472 113
103 32 15 16 5345 19 178 32 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]Construindo o modelo
Uma rede neural artificial é formado por um conjunto de camadas. Essas camadas extraem representações dos dados de entrada que tendem a ser mais significativas para a resolução do problema. Basicamente, as redes neurais requerem duas principais decisões arquitetural:
- Quantas camadas será usada no modelo?
- Quantas neurônios (unidades) cada camada irá conter?
Neste exemplo, a entrada consiste um array do tipo índice-palavra. Os rótulos possuem apenas dois valores: 0 ou 1. Vamos construir o modelo para esse problema:
# input shape is the vocabulary count used for the movie reviews (10,000 words)
vocab_size = 10000
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160000
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 16) 272
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________O que cada camada faz é o seguinte:
- A primeira camada é do tipo
Embedding. Esta camada toma a palavra codificada e mapeia um vetor embutido (embedding) para cada índice-palavra. Esses vetores embutidos são aprimorados a medida que o modelo treina. Essa camada adiciona uma dimensão extra no formato da saída (batch, sequence, embedding). Portanto, podemos dizer que o objetivo dessa camada é criar uma representação menor quemax_lendos dados de entrada. - Em seguida, a camada
GlobalAveragePooling1Dretorna um vetor de saída de tamanho fixo para cada exemplo extraindo a média sobre a dimensão da sequência. Isto permite o modelo manipular a entrada de tamanho variado da maneira mais simples possível. - E saída da camada anterior é plugada em uma camada densamente conectada (Dense) com 16 unidades.
- A última camada também é densamente conectada e possui apenas 1 unidade. Ao usar a função de ativação
sigmoide, o resultado é do tipo float entre 0 e 1, representando a probabilidade, ou o nível de confiança.
A respeito dos neurônios
O modelo acima tem duas camadas intermediárias ou "ocultas", entre a entrada e a saída. O número de saídas (unidades, nós ou neurônios) é a dimensão do espaço representacional da camada. Em outras palavras, a quantidade de liberdade que a rede é permitida ao aprender uma representação interna.
Se um modelo tiver mais unidades ocultas (um espaço de representação de dimensão mais alta) e / ou mais camadas, a rede poderá aprender representações mais complexas. No entanto, isso torna a rede mais onerosa e pode levar ao aprendizado de padrões indesejados - padrões que melhoram o desempenho nos dados de treinamento, mas não nos dados de teste. Isso é chamado overfitting e será explorado mais tarde.
A respeito da função custo e otimizador
Um modelo precisa de uma função custo e um otimizador para treinamento. Como esse é um problema de classificação binária e as saídas do modelo são uma probabilidade (uma camada densa de 1 unidade com uma ativação sigmóide), usamos a função custo binary_crossentropy.
Esta não é a única opção para uma função custo, você poderia, por exemplo, escolher mean_squared_error. Mas, geralmente, a binary_crossentropy é melhor para lidar com probabilidades - ela mede a "distância" entre distribuições de probabilidade, ou, no nosso caso, entre a distribuição real e as previsões.
No próximo artigo, quando estivermos explorando problemas de regressão (por exemplo, para prever o preço de uma casa), veremos como usar outra função custo erro médio quadrático.
O código a seguir compila a estrutura criada usando a função custo binary_crossentropy e o otimizador AdamOptimizer:
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='binary_crossentropy',
metrics=['accuracy'])Treinando o modelo
No treinamento, queremos checar a acurácia do modelo sobre uma porção de dados que ainda não foram vistos. Essa porção se chama dados de validação. Vamos criar um conjunto de validação separando uma parte dos 10.000 exemplos dos dados de treinamento original. E por que não usar os dados de teste? O objetivo é desenvolver e ajustar o modelo usando apenas dados para treinamento, enquanto que os dados de teste serão usados apenas para medir o desempenho do modelo. Vamos dividir os dados da seguinte maneira:
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]Vamos configurar o modelo para que rode em 40 épocas e utilize mini lotes de 512 amostras. Estas 40 iterações sobre todas as amostras nos tensores partial_x_train e partial_y_train. Durante o treino, monitore o erro e a acurácia do modelo sobre as 10.000 amostras no conjunto de validação x_val e y_val.
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)Train on 15000 samples, validate on 10000 samples
Epoch 1/40
15000/15000 [==============================] - 1s 57us/step - loss: 0.6914 - acc: 0.5662 - val_loss: 0.6886 - val_acc: 0.6416
Epoch 2/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.6841 - acc: 0.7016 - val_loss: 0.6792 - val_acc: 0.6751
Epoch 3/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.6706 - acc: 0.7347 - val_loss: 0.6627 - val_acc: 0.7228
Epoch 4/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.6481 - acc: 0.7403 - val_loss: 0.6376 - val_acc: 0.7774
Epoch 5/40
15000/15000 [==============================] - 1s 40us/step - loss: 0.6150 - acc: 0.7941 - val_loss: 0.6017 - val_acc: 0.7862
Epoch 6/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.5719 - acc: 0.8171 - val_loss: 0.5596 - val_acc: 0.7996
Epoch 7/40
15000/15000 [==============================] - 1s 43us/step - loss: 0.5230 - acc: 0.8400 - val_loss: 0.5145 - val_acc: 0.8266
Epoch 8/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.4738 - acc: 0.8559 - val_loss: 0.4717 - val_acc: 0.8407
Epoch 9/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.4288 - acc: 0.8671 - val_loss: 0.4343 - val_acc: 0.8500
Epoch 10/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.3889 - acc: 0.8794 - val_loss: 0.4034 - val_acc: 0.8558
Epoch 11/40
15000/15000 [==============================] - 1s 43us/step - loss: 0.3558 - acc: 0.8875 - val_loss: 0.3805 - val_acc: 0.8607
Epoch 12/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.3285 - acc: 0.8942 - val_loss: 0.3585 - val_acc: 0.8675
Epoch 13/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.3039 - acc: 0.9001 - val_loss: 0.3432 - val_acc: 0.8707
Epoch 14/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.2836 - acc: 0.9056 - val_loss: 0.3299 - val_acc: 0.8739
Epoch 15/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.2661 - acc: 0.9102 - val_loss: 0.3197 - val_acc: 0.8766
Epoch 16/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.2512 - acc: 0.9145 - val_loss: 0.3114 - val_acc: 0.8780
Epoch 17/40
15000/15000 [==============================] - 1s 39us/step - loss: 0.2368 - acc: 0.9196 - val_loss: 0.3046 - val_acc: 0.8800
Epoch 18/40
15000/15000 [==============================] - 1s 43us/step - loss: 0.2244 - acc: 0.9235 - val_loss: 0.2991 - val_acc: 0.8820
Epoch 19/40
15000/15000 [==============================] - 1s 44us/step - loss: 0.2129 - acc: 0.9279 - val_loss: 0.2950 - val_acc: 0.8825
Epoch 20/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.2027 - acc: 0.9313 - val_loss: 0.2912 - val_acc: 0.8826
Epoch 21/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1929 - acc: 0.9357 - val_loss: 0.2884 - val_acc: 0.8836
Epoch 22/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1840 - acc: 0.9394 - val_loss: 0.2868 - val_acc: 0.8843
Epoch 23/40
15000/15000 [==============================] - 1s 40us/step - loss: 0.1758 - acc: 0.9429 - val_loss: 0.2856 - val_acc: 0.8840
Epoch 24/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1677 - acc: 0.9475 - val_loss: 0.2842 - val_acc: 0.8850
Epoch 25/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1606 - acc: 0.9503 - val_loss: 0.2838 - val_acc: 0.8847
Epoch 26/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.1535 - acc: 0.9526 - val_loss: 0.2839 - val_acc: 0.8853
Epoch 27/40
15000/15000 [==============================] - 1s 43us/step - loss: 0.1475 - acc: 0.9547 - val_loss: 0.2851 - val_acc: 0.8841
Epoch 28/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.1414 - acc: 0.9571 - val_loss: 0.2848 - val_acc: 0.8862
Epoch 29/40
15000/15000 [==============================] - 1s 39us/step - loss: 0.1356 - acc: 0.9585 - val_loss: 0.2859 - val_acc: 0.8860
Epoch 30/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1307 - acc: 0.9617 - val_loss: 0.2877 - val_acc: 0.8864
Epoch 31/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1248 - acc: 0.9645 - val_loss: 0.2893 - val_acc: 0.8856
Epoch 32/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1202 - acc: 0.9660 - val_loss: 0.2916 - val_acc: 0.8844
Epoch 33/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1149 - acc: 0.9685 - val_loss: 0.2936 - val_acc: 0.8853
Epoch 34/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1107 - acc: 0.9695 - val_loss: 0.2971 - val_acc: 0.8845
Epoch 35/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.1069 - acc: 0.9707 - val_loss: 0.2987 - val_acc: 0.8854
Epoch 36/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.1021 - acc: 0.9731 - val_loss: 0.3019 - val_acc: 0.8842
Epoch 37/40
15000/15000 [==============================] - 1s 43us/step - loss: 0.0984 - acc: 0.9747 - val_loss: 0.3050 - val_acc: 0.8833
Epoch 38/40
15000/15000 [==============================] - 1s 42us/step - loss: 0.0951 - acc: 0.9753 - val_loss: 0.3089 - val_acc: 0.8826
Epoch 39/40
15000/15000 [==============================] - 1s 43us/step - loss: 0.0911 - acc: 0.9773 - val_loss: 0.3111 - val_acc: 0.8829
Epoch 40/40
15000/15000 [==============================] - 1s 41us/step - loss: 0.0876 - acc: 0.9795 - val_loss: 0.3149 - val_acc: 0.8829Avaliar o modelo
Uma vez treinado, podemos avaliar o modelo usando o método evaluate que irá retorna, nesse caso, o erro (quanto menor, melhor) e a acurácia (quanto maior, melhor).
results = model.evaluate(test_data, test_labels)
print(results)25000/25000 [==============================] - 1s 36us/step
[0.33615295355796815, 0.87196]Esta abordagem bastante simples alcança uma precisão de cerca de 87%. Com abordagens mais avançadas, o modelo deve se aproximar de 95%.
Construir o gráfico do erro e da acurácia
A chamada model.fit() retorna um objeto History que contém um dicionário com tudo o que rolou durante o treinamento.
history_dict = history.history
history_dict.keys()dict_keys(['acc', 'val_loss', 'loss', 'val_acc'])Existem quatro entradas: uma para cada métrica monitorada durante o treino e a validação. Podemos usá-los para plotar o erro de treino e validação para comparação, bem como a acurácia do treino e validação:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()plt.clf() # clear figure
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()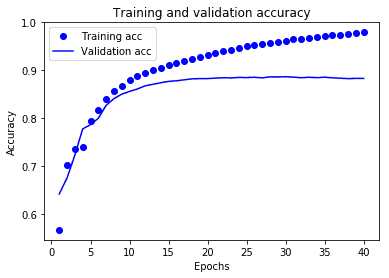
Neste gráfico, os pontos representam o erro e a acurácia do treinamento, e as linhas sólidas são o erro e a acurácia da validação. Observe que o erro de treino diminui a cada época e a acurácia do treino aumenta a cada época. Isso é esperado ao usar uma otimização de gradiente descendente - deve minimizar a quantidade desejada em cada iteração.
Este não é o caso da erro e acurácia da validação - elas parecem atingir o pico após cerca de vinte épocas. Este é um exemplo de overfitting: o modelo tem um desempenho melhor nos dados de treinamento do que em dados que nunca viu antes. Depois desse ponto, o modelo otimiza demais e aprende representações específicas dos dados de treinamento que não são generalizados para testar dados.
Para este caso em particular, poderíamos evitar overfitting simplesmente parando o treinamento depois de aproximadamente vinte épocas. Mais tarde, você verá como fazer isso automaticamente com um retorno de chamada (callback).
#@title MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.Resumo
Neste post, você acompanhou o passo a passo de como criar e treinar um modelo de aprendizado de máquina para classificar uma avaliação de filmes em positiva ou negativa com a base de dados do portal IMDb utilizando o biblioteca de alto nível Keras que acompanha o TensorFlow. Os tópicos que você aprendeu foram:
- Como explorar seu conjunto de dados de modo que você tenha um entendimento melhor dos dados que você tem em mãos para treinar seu modelo
- Como configurar e compilar seu modelo usando a API de alto nível Keras disponível no TensorFlow
- Como visualizar o histórico de erros e acurácia de seu modelo
Agradecemos sua visita, e desejamos que tenham gostado do post e que ele possa ter contribuído de alguma forma para sua carreira. Se ficou com alguma dúvida sobre como treinar sua primeira rede neural com o TensorFlow, utilize o espaço reservado para comentários abaixo. Se esse conteúdo foi útili para você, com uma linguagem clara e objetiva, ajude-nos a compartilhar com outras pessoas.

